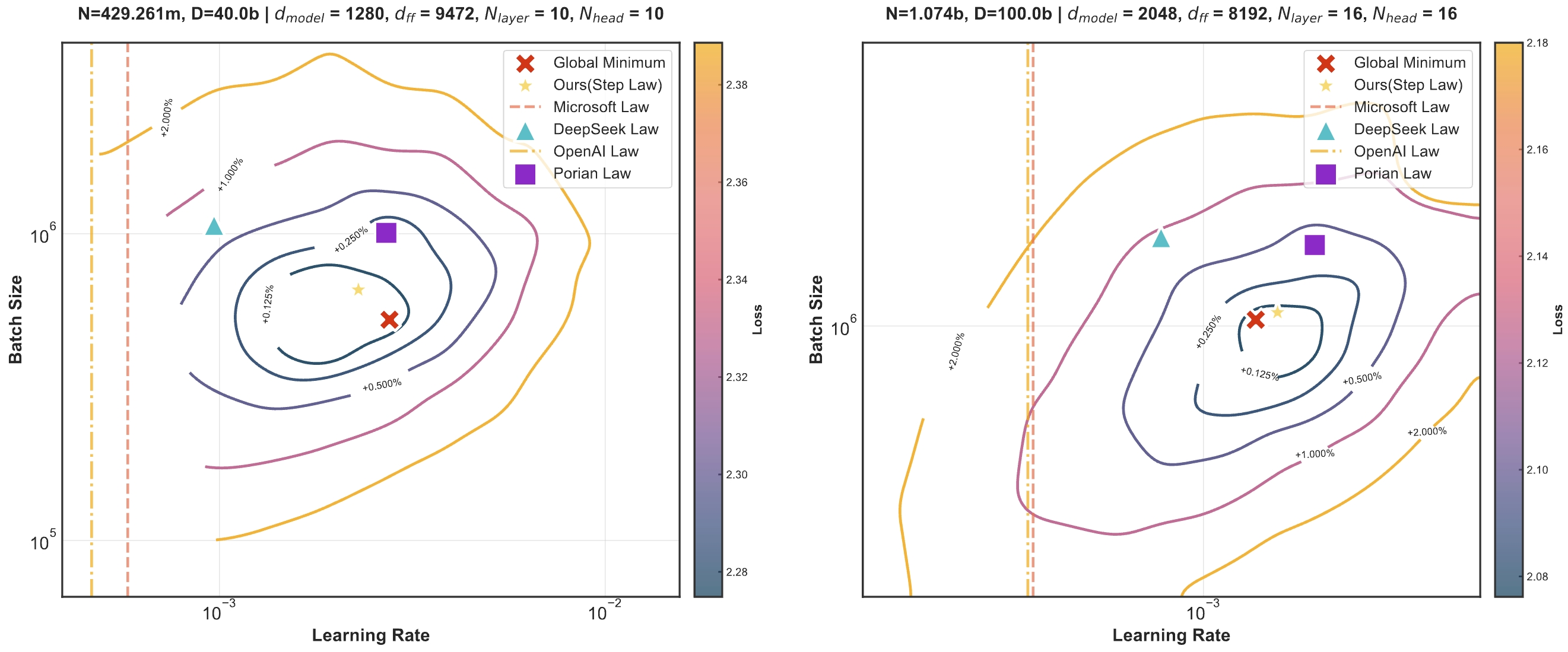
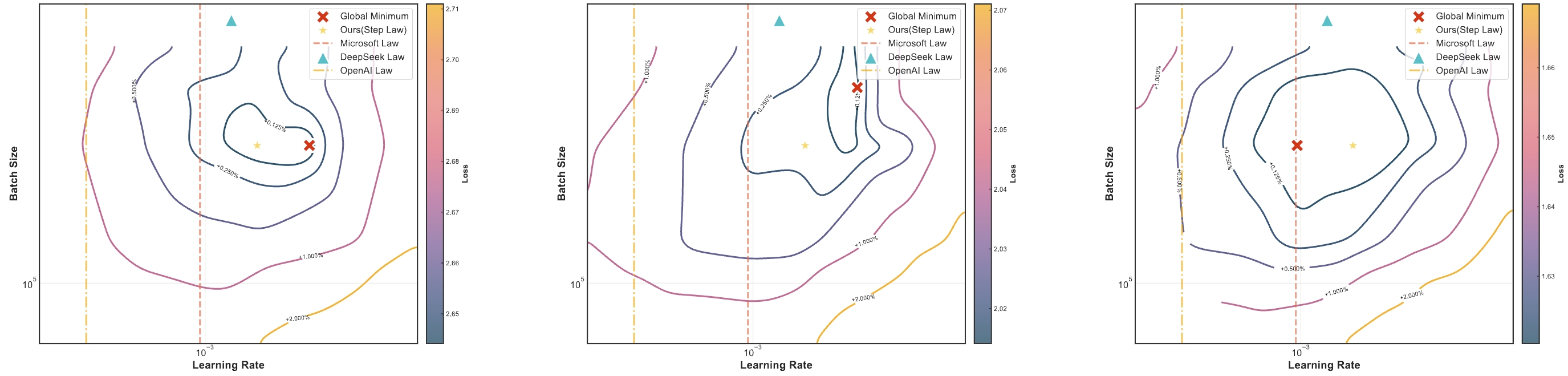
We first present the unified optimal hyperparameter scaling laws, termed Step Law, that generalizes across diverse model shapes, architectures, and data distributions.
Our findings demonstrate remarkable accuracy, with estimated values on test sets deviating by only 0.09% from the globally optimal LLM performance identified through exhaustive search.
This research entails a significant computational investment, utilizing nearly one million NVIDIA H800 GPU hours to train 3,700 LLMs of varying sizes and hyperparameters from scratch, consuming approximately 100 trillion tokens in total. To support reproducibility and advance the field for LLM pre-training, we will progressively release all loss measurements and model checkpoints through our designated repository. The universal, plug-and-play optimal hyperparameter tool is provided for the community.
Step Law demonstrates that the optimal batch size $B(D)$ exhibits a primary dependence on dataset size $D$, while the optimal learning rate $\eta(N, D)$ manifests a joint dependence on both model parameters $N$ and dataset size $D$.
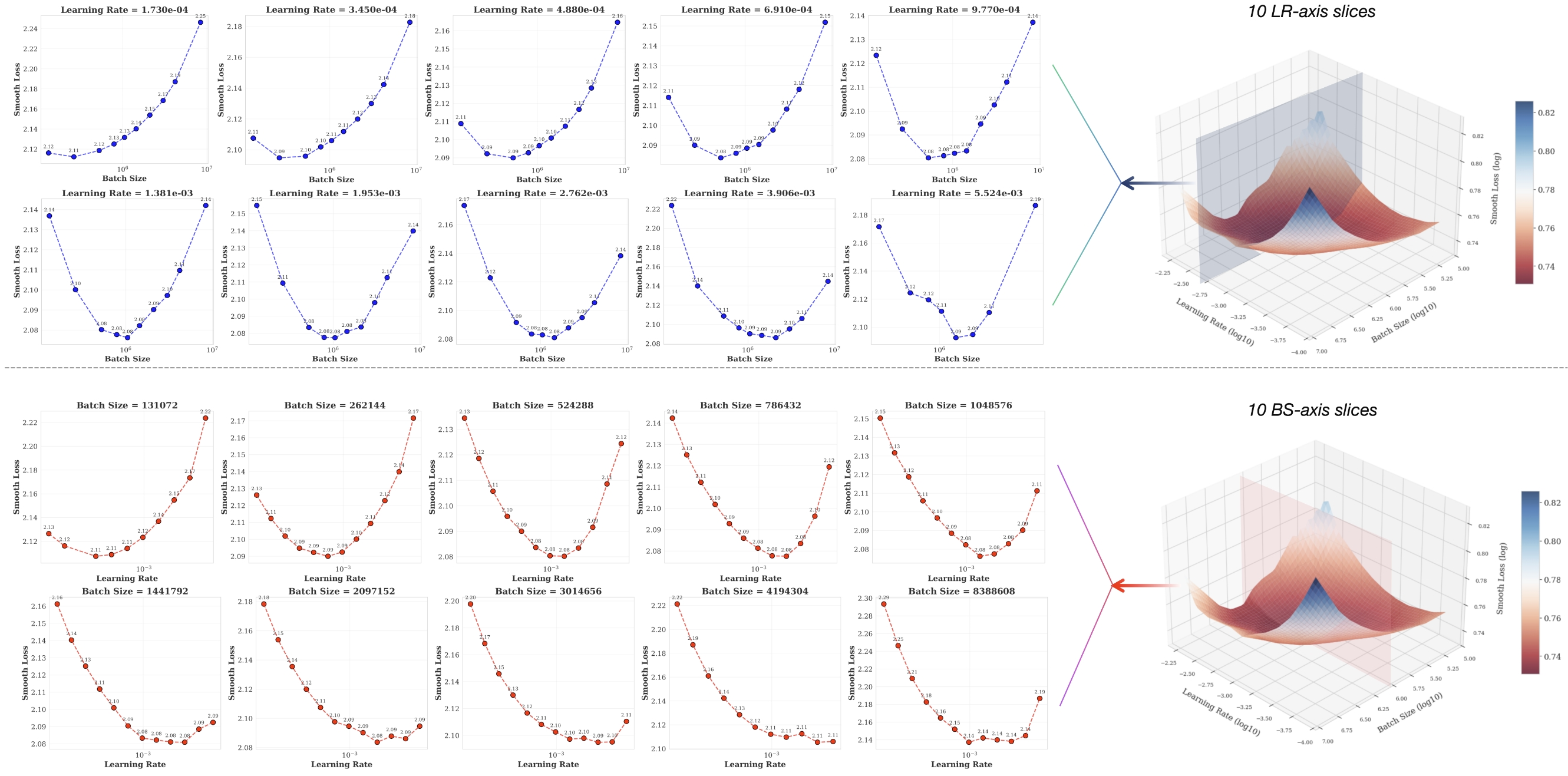
We discover and demonstrate the convexity property of the loss landscape under fixed parameter count and data size conditions. This provides fundamental insights into hyperparameter optimization.
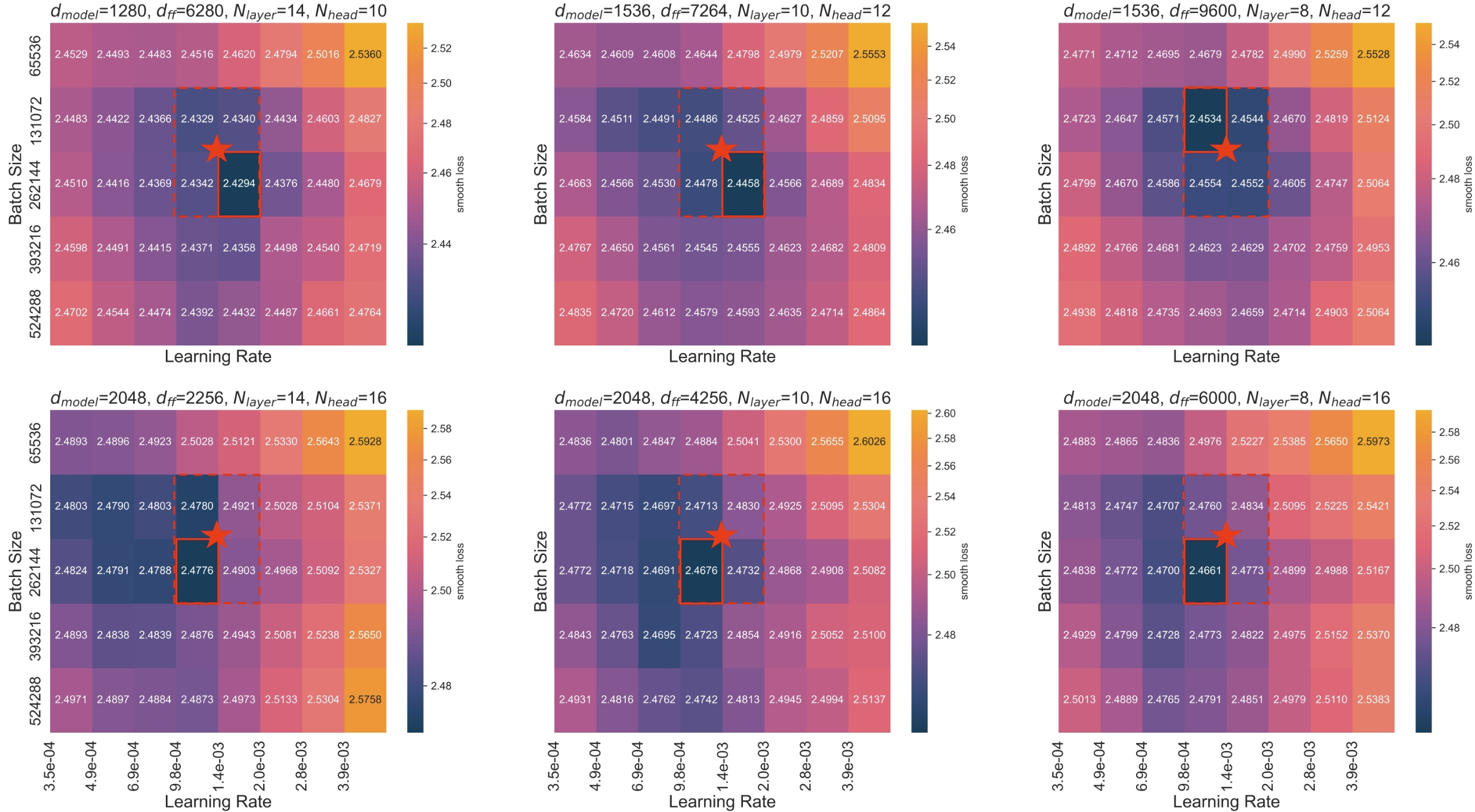
We conduct a comprehensive investigation into how different model architectures (specifically varying combinations of width and depth dimensions) influence scaling laws. Our findings demonstrate that Step Law exhibits a high degree of stability across all architectural configurations.
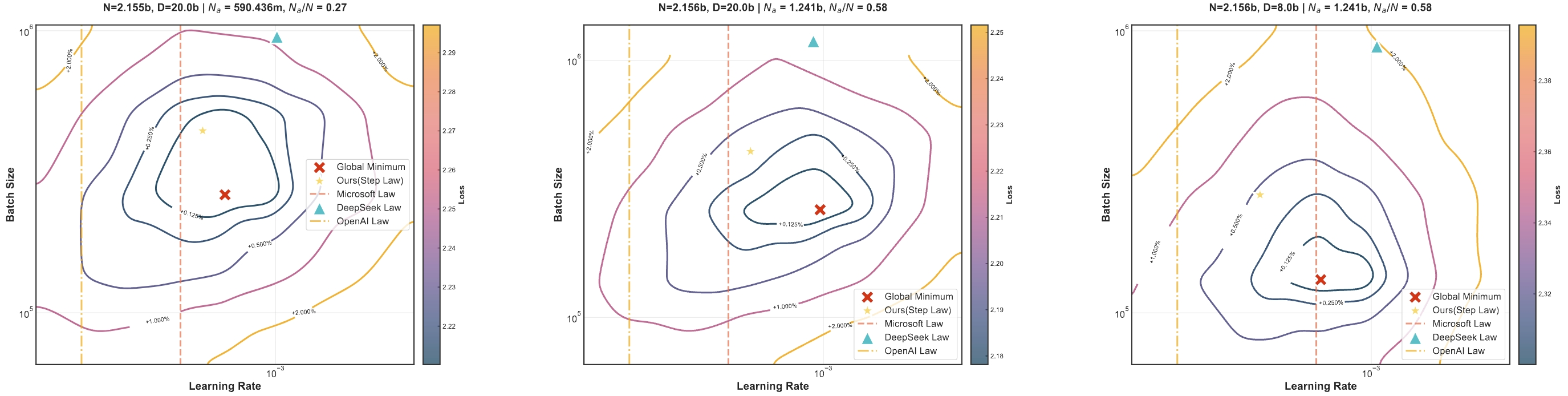
Besides, our research findings reveal that this scaling law not only applies to dense models but also generalizes effectively to MoE models with varying sparsity levels, demonstrating robust generalization capabilities.
Our experiment further validates the consistency of Step Law across diverse data distributions: whether in English-dominated, Chinese-English mixed, Code-English mixed, or Code-dominant, the Step Law demonstrates stable performance. This provides robust support for its practical applications in multilingual and multitask settings.
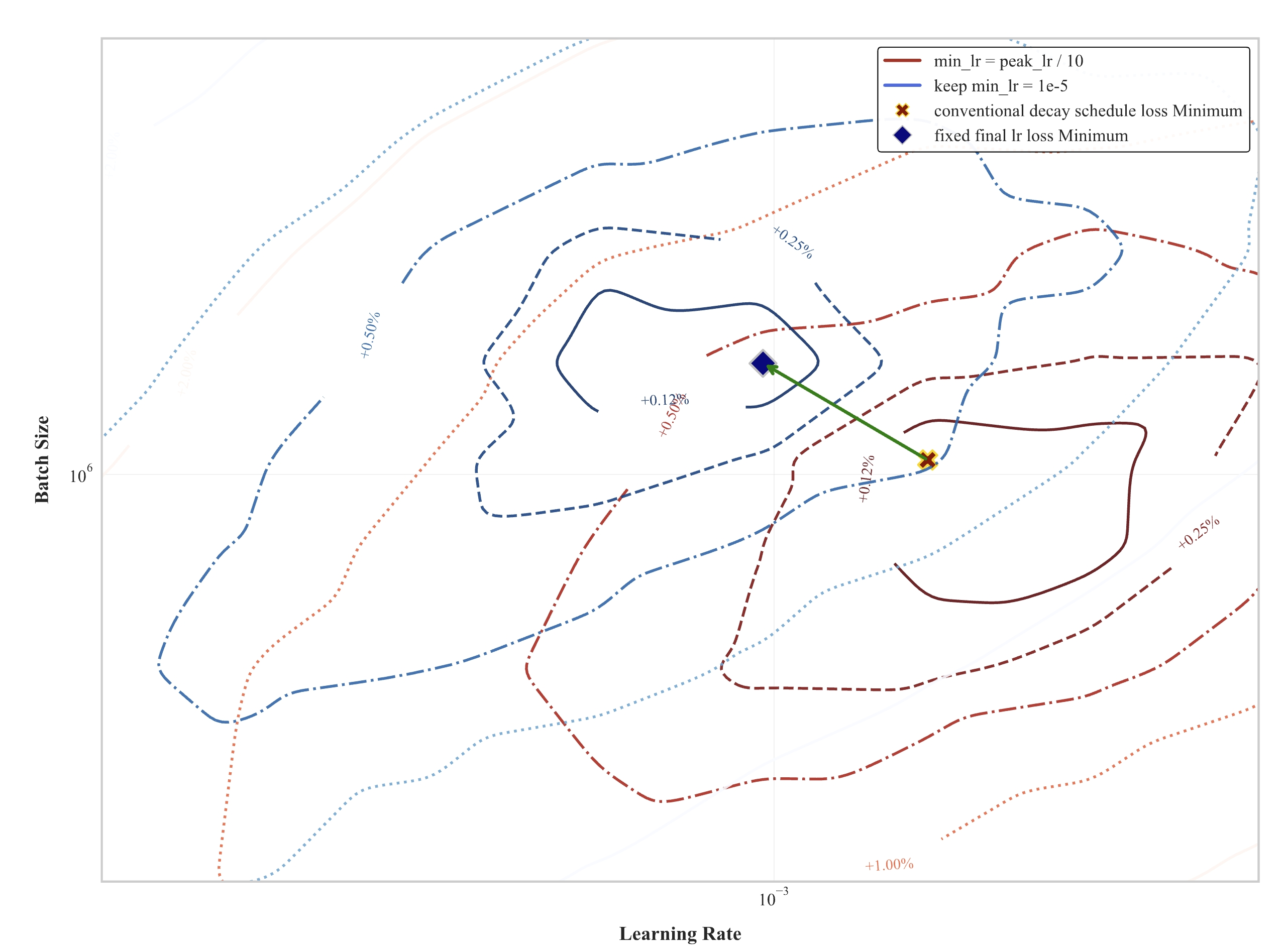
Our comparative analysis reveals that learning rate scheduling strategies significantly impact optimal hyperparameter selection. The experiment further uncovers critical distinctions between traditional learning rate decay and fixed minimum learning rate schemes.
Through logarithmic transformation of power-law relationships into linear forms, parameters are fitted via the least squares method, with robustness enhanced through bootstrap sampling. We provide a precise predictive formula, establishing a theoretical foundation for hyperparameter configuration in LLMs pretraining.
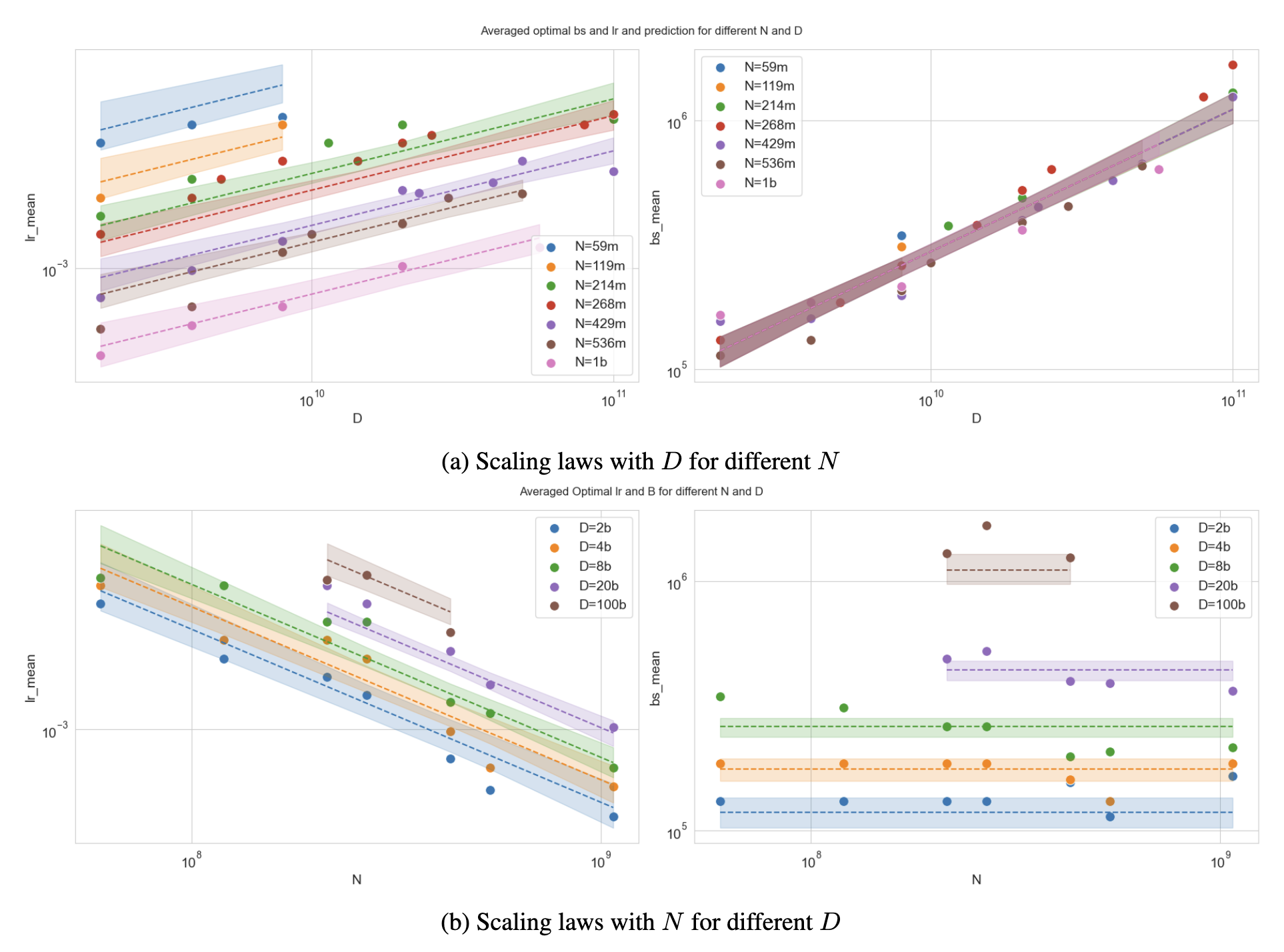
Figure 7. (a) Scatter points indicate empirical optimal learning rate vs. batch size for model scale N; (b) Analogous results for dataset scale D.
Curves show our hp-scaling law predictions, with shaded regions representing parameter uncertainty bounds from the sampling-based fitting strategy. Each data point in the figures represents between 45 and 120 independently trained models with distinct hyperparameters. Every plotted position corresponds to the optimal hyperparameter configuration (Optimal Learning Rate and Optimal Batch Size) identified through grid search under varying model sizes and data scales. Both plots use double logarithmic scaling (1912 training samples).Live Progress Tracking
@misc{li2025predictablescalei,
title = {Predictable Scale: Part I -- Optimal Hyperparameter Scaling Law in Large Language Model Pretraining},
author = {Houyi Li and Wenzhen Zheng and Qiufeng Wang and Hanshan Zhang and Zili Wang and Shijie Xuyang and Yuantao Fan and Zhenyu Ding and Haoying Wang and Ning Ding and Shuigeng Zhou and Xiangyu Zhang and Daxin Jiang},
year = {2025},
eprint = {2503.04715},
archivePrefix = {arXiv},
primaryClass = {cs.LG},
url = {https://arxiv.org/abs/2503.04715},
}